이 글은 책 『오라클 튜닝 에센셜』의 내용을 기반으로 작성했습니다
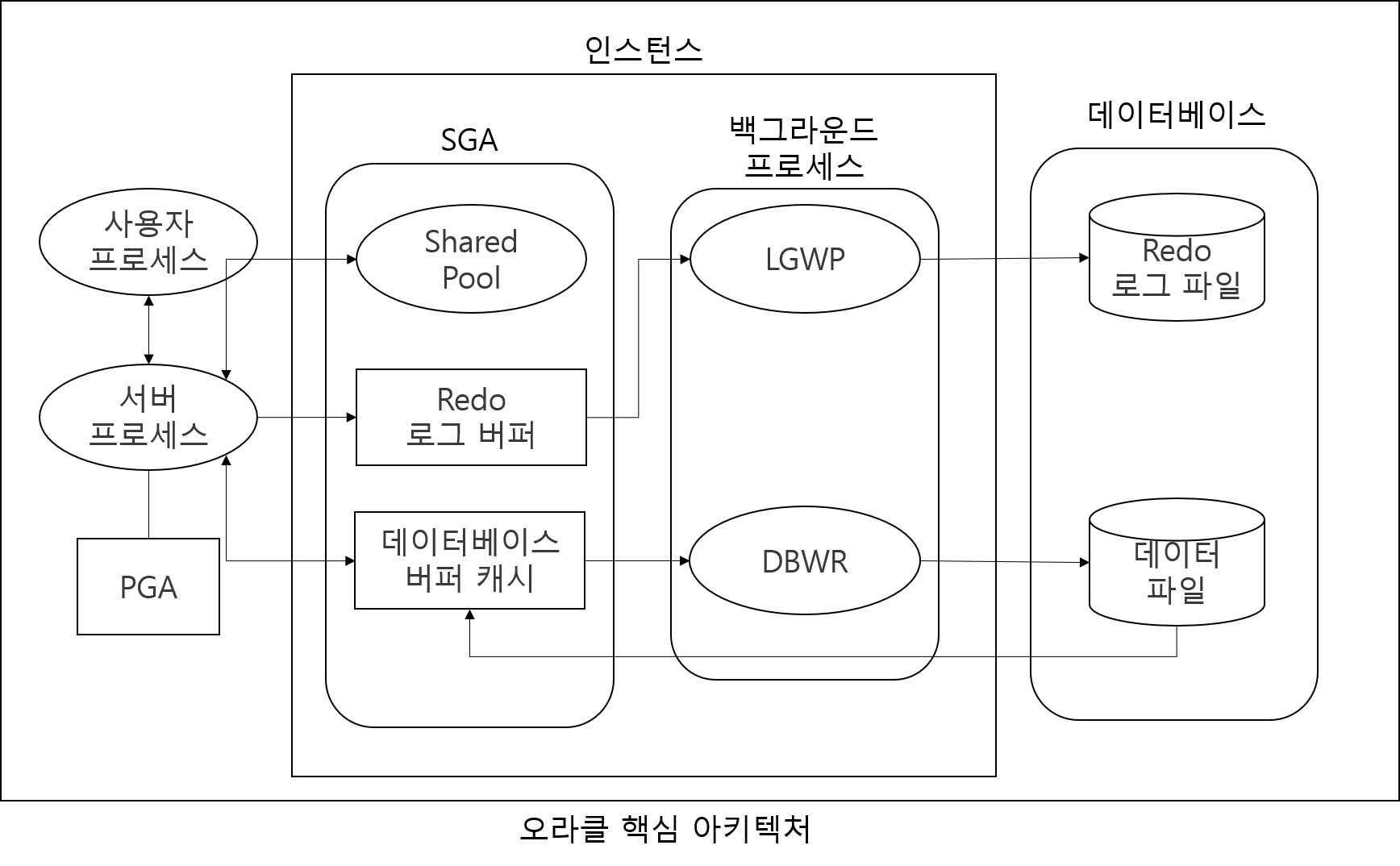
오라클 아키텍처는 실제로 더 복잡하지만, 간단하게 보도록하자. 위와 같은 그림으로 본다고 하고 각자 하는 역할이 무엇인지 살펴보도록 하자.
INSERT 쿼리 동작 과정
예시 쿼리
INSERT INTO test_table(num) VALUES 10
- 쿼리를 실행한다
- 서버프로세스가 문법이 맞는지 확인한다.
- test_table이 있는지 num이라는 칼럼이 있는지, 10을 저장할 수 있는지 확인한다
- sql문을 실행한 계정이 test_table에 insert할 수 있는 권한을 가지고 있는지 검사한다
- insert문을 재사용하기 위해 해당 쿼리를 shared pool에 저장한다
- 쿼리가 실행되면 10이라는 값을 Redo 로그 버퍼에 저장한다
- 데이터베이스 버퍼 캐시에 저장한다 (여기까지는 물리적으로 데이터를 저장하지 않는다)
COMMIT- LGWR(Log Writer)는 프로세스가 Redo 로그 버퍼에 있는 내용을 Redo 로그 파일에 저장한다
- DB 버퍼 캐시가 더티 버퍼(Dirty Buffer)로 상태가 바뀐다
- Checkpointer는 데이터 파일에 저장하기 위해 DBWR(Database Writer)에게 신호를 보내고 DBWR은 데이터 파일에 기록한다
‘SELECT’ 쿼리 동작 과정
예시 쿼리
SELECT * FROM test_table
- 문법이 맞는지 확인한다
- 쿼리문에 열거된 테이블, 칼럼명이 실제로 있는지 확인한다
- test_table
select를 수행할 수 있는 권한이 있는지 확인한다 - shared pool에
select문을 저장한다 - test_table 테이블의 데이터가 어디있는지 확인한다
- 서버 프로세스가 db 버퍼 캐시에 있는지 확인한다
- 캐시에 없으면 디스크에 가서 테이블 데이터를 db 버퍼 캐시로 복사한다
- db 버퍼 캐시에 적재된 데이터 중 sql문의 결과를 유저프로세스로 전송한다
Redo Log Buffer와 LGWR
데이터가 변경되면 서버프로세스는 Redo Log Buffer에 기록한다 LGWR는 적절한 시점에 Redo Log Buffer의 내용을 로그 파일로 저장한다 오라클에서 정한 적절한 시점은 다음과 같다
- 매 3초마다
- Redo Log Buffer가 1/3 채워졌을 때
- 변경된 Redo Log Buffer가 1MB 이상 됐을 때
- 사용자가
commit명령을 내렸을 때
사용자가 commit을 했을 때 그 때까지 저장되지 않은 Redo Log Buffer에 있는 내용을 모두 Redo Log에 저장한다. 그때까지 디스크에 파일로 저장하지 않는 것이다. 오라클은 갑작스러운 장애가 발생했을 때, 백업 기준으로 데이터를 복구하고 백업 이후 내용은 Redo Log File에 기록된 내용에서 오늘 시점까지 복구한다.
DB 버퍼 캐시와 DBWR
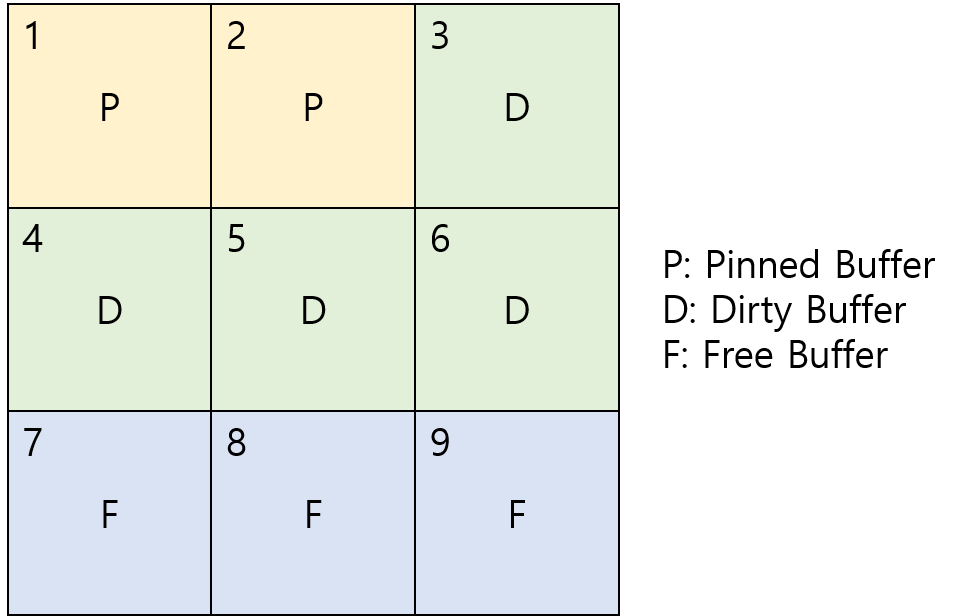 DB 버퍼 캐시 상태
DB 버퍼 캐시 상태
위 그림은 DB 버퍼 캐시 상태를 나타낸다. 1~9는 블록 주소라고 가정한다. 먼저 P, D, F가 뭔지 살펴본다
- 핀드 버퍼(Pinned Buffer): 어떤 사용자가 현재 사용중인 버퍼이다. 데이터는 변경되었지만 아직
commit되지 않았다. - 더티 버퍼(Dirty Buffer): 어떤 사용자가 사용을 완료(
commit) 했으나 데이터 파일에 저장되지 않은 상태. 현재 상태에서는 사용할 수 없다 - 프리 버퍼(Free Buffer): 사용되지 않았거나 더티 버퍼에 있는 데이터를 데이터 파일에 저장하고 다시 사용 가능한 블럭이다
오라클에서 데이터가 변경 혹은 추가 된 이후 commit 명령을 내리면 LGWR이 Redo Log 파일에 저장한다. 그리고 해당 버퍼의 Pinned 상태에서 Dirty 상태로 변경된다. DB 버퍼 캐시에 변경된 데이터를 저장하는 역할은 DBWR이 한다.
버퍼 캐시에 Dirty 캐시가 있고, DBWR이 작동할 때 DB버퍼 캐시에 있는 해당 블록을 통째로 가져다 DB 파일에 저장하게 된다. SELECT의 경우도 DB파일에 있는 필요한 블록을 DB버퍼 캐시에 통째로 복사한다.
DBWR이 DB 버퍼 캐시 내 블록을 변경하고 저장이 필요한 블록을 찾아서 디스크의 데이터 파일로 저장하는 경우는 다양하다. 그 중 일부는 다음과 같다
- Checkpoint 신호가 발생했을 때
- Direct Path Read/Write가 진행될 때
- DROP TABLE 또는 TRUNCATE TABLE 명령이 실행될 때
commit 이후에 LGWR이 Redo Log Buffer에 기록된 데이터를 Redo Log 파일에 저장한 다음 DBWR에 알려주지 않으면 나중에 DBWR의 작업량이 늘어날 수가 있다. 그래서 Checkpoint 신호가 DBWR에게 저장 가능한 버퍼를 저장하도록 신호를 준다.
오라클은 대부분의 데이터를 DB 버퍼 캐시에 불러와 처리한다. 하지만 대용량 데이터를 처리할 경우 DB 버퍼 캐시를 경유하면 부하가 발생할 수 있다. 이럴 때 사용되는 것이 Read/Write다.
테이블 데이터를 DELETE명령으로 삭제할 경우에는 롤백 명령이 내려질 수도 있으므로 이에 대비해야 하지만, DROP TABLE이나 TRUNCATE TABLE같은 DDL문장은 따로 COMMIT이나 롤백을 하지 않으므로 DB 버퍼 캐시는 바로 기록 후 처리한다.
Shared pool
 Shared Pool 구조
Shared Pool 구조
Shared Pool의 내부 구조는 크게 라이브러리 캐시(Library Cache)와 딕셔너리 캐시(Dictionary Cache)가 있다.
- 라이브러리 캐시: 파싱된 SQL문과 실행계획을 매핑하여 저장한다. 이미 한번 실행된 SQL문을 재사용 할때는 라이브러리 캐시에 저장된 실행계획을 찾아 최적의 경로를 찾는다.
- 딕셔너리 캐시: 오라클이 가진 모든 객체(테이블, 뷰, 프로시저 등)에 대한 정보가 들어있다. 오라클이 어떤 테이블의 데이터를 찾을 때, 그 시작 지점은 딕셔너리 캐시가 된다.
SQL 실행 과정
SELECT문을 먼저 살펴보도록 한다. 다음과 같은 순서로 진행된다.
- 구문분석(Parse)
- 값 치환(Bind)
- 실행(Execute)
- 데이터 인출(Fetch)
구문분석(Parse)
서버프로세스는 유저프로세스를 통해 전송된 SELECT문이 실행 가능한지 검사한다. 문법 검사, 의미 검사, 권한 검사를 진행한다.
- 문법 검사: 올바른 SQL 문법인지 확인한다
- 의미 검사:
FROM절의 유형이 테이블인지 뷰이인지 시노님인지 확인- 해당 오브젝트에 칼럼이 있는지 확인
- 최적화 단계
- 테이블, 인덱스, 칼럼에 대한 통계 정보가 존재하는지 확인
WHERE절의 칼럼에 인덱스가 존재하는지, 존재한다면 인덱스를 이용하는게 더 좋은지- 실행 계획 생성 이러한 과정들을 매번 반복한다면 매우 비효율적일 수가 있다. 오라클은 한번 사용한 SQL문을 재사용하기 위해 실행계획과 함께 저장하는데 그 저장 장소가 Shared Pool의 라이브러리 캐시다.
값 치환(Bind)
구문 분석의 비용이 크기 때문에, 위와 같은 과정을 다시 거치지 않기 위해 조건에 대한 값을 변수를 통해 담는다.
SELECT * FROM EMP WHERE MGR = 7788
SELECT * FROM EMP WHERE MGR = 7900
SELECT * FROM EMP WHERE MGR = :mgr
위 세 개의 SQL문은 서로 다르기 때문에 세번의 구문분석을 거친다. 그러나 세번째 sql문 경우에는 mgr변수에 값을 대입하면 된다. 구문분석 단계를 한번으로 줄이고, 두번째 실행할 경우에는 라이브러리 캐시에서 이전에 저장한 실행 계획을 찾아서 진행한다.
실행(Execute)
서버프로세스는 최적의 경로와 바인딩된 값이 있는 실제 데이터를 찾는다. DB 캐시에 먼저 찾아보고 없으면 데이터 파일에서 해당 블록을 DB 버퍼 캐시로 복사한다.
데이터 인출(Fetch)
원하는 데이터가 DB 버퍼 캐시에 적재되어 있고, 마지막으로 조건에 맞는 데이터를 걸러내는 작업을 한다. 이를 걸러내고 사용자에게 전송한다.
SELECT 문장의 논리적 실행 순서
SELECT 칼럼명 -- 5
FROM 테이블명 -- 1
WHERE 조건식 -- 2
GROUP BY 칼럼 또는 표현식 -- 3
HAVING 그룹 조건식 -- 4
ORDER BY 칼럼 또는 표현식 -- 6
위와 같은 방식으로 실행하기 때문에 만일 SELECT 칼럼명에서 정의한 ALIAS 이름을 GROUP BY에서 사용하려고 하면 에러가 날 것이다.
이 것이 논리적 실행 순서를 말하는 것이지 실제 실행 순서를 의미하지는 않는다. 실제 동작하는 실행 순서는 실행 계획을 통해 알 수 있다.
데이터 저장 구조
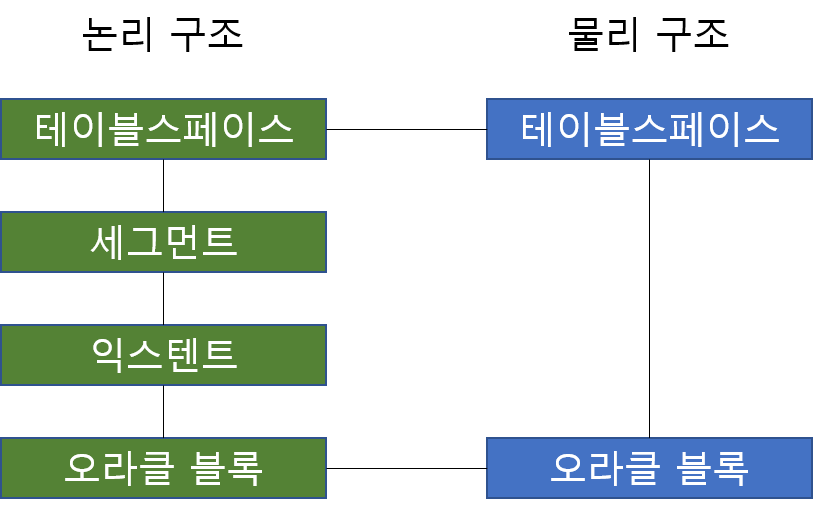 오라클 데이터 구조
오라클 데이터 구조
오라클 데이터 구조는 오라클이 자체적으로 정한 논리 구조와 운영체제가 관리하는 물리 구조가 있다.
테이블스페이스(Tablespace)
논리 구조의 가장 상단에 위치해 있고 물리 구조의 데이터 파일을 1개 이상 가지고 있다. 테이블 스페이스는 의미상 논리적으로 연관성이 있는 데이터를 묶어주는 역할을 한다. 물리적으로 한 개 이상의 파일이 필요하더라도 테이블 스페이스가 어떤 파일에 데이터가 저장되어 있는지 관리한다.
세그먼트(Segment)
테이블과 거의 일치하는 구조라고 생각하면 편하다. 파티션 테이블의 파티션을 제외하고 테이블과 1:1구조라고 생각할 수 있다.
익스텐트(Extent)
오라클 블록을 논리적으로 인접한 블록으로 관리하는 단위다. 세그먼트가 저장 구조에 대한 논리적인 단위면, 익스텐트는 저장할 수 있는 공간을 만드는 단위다. 세그먼트는 익스텐트 한 개 이상을 가질 때 데이터를 저장할 수 있다. 익스텐트에서는 다른 구조와 다르게 논리적으로 연속된 오라클 블록을 가진다.
블록(Block)
오라클의 가장 기본이 되는 I/O 단위로 모든 데이터는 블록 안에 저장되어 있다. 오라클은 저장을 하거나 저장된 데이터를 불러올 때 블록보다 작은 단위로 가져올 수 없다. 오라클 블록은 2~64KB까지 사용가능하고 기본값은 8KB이다.
 오라클 블록 구조
오라클 블록 구조
오라클 블록은 크게 헤더, 프리 스페이스, 데이터 영역으로 나뉜다. 헤더에는 여러 정보가 담기고 가장 중요한 것은 데이터를 변경할 때 어느 요청이 먼저 사용할지를 결정할 수 있는 정보다. 이를 위해 사용하는 일종의 명단을 ITL(Interested Transaction List)라고 한다. 프리스페이스는 변경을 위해 약간 남겨둔다. 예를 들어 ‘ABC’ 에서 ‘ABCD’로 변경할 때 이미 저장된 데이터가 변경되면서 크기가 늘어났을 경우를 대비하는 공간이다.
정리
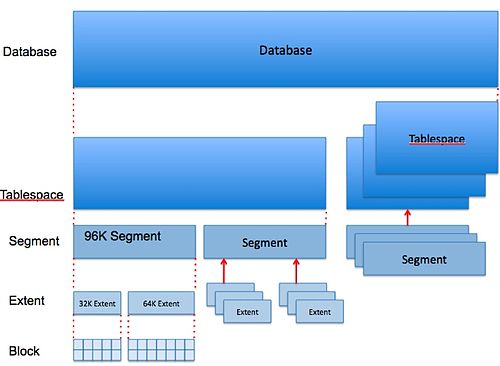 오라클 논리 구조
오라클 논리 구조
오라클 논리적 형태는 최종적으로 위와 같이 보인다