카프카 주요 특징
높은 처리량과 낮은 지연시간
카프카는 매우 높은 처리량과 낮은 지연시간을 자랑한다.
| 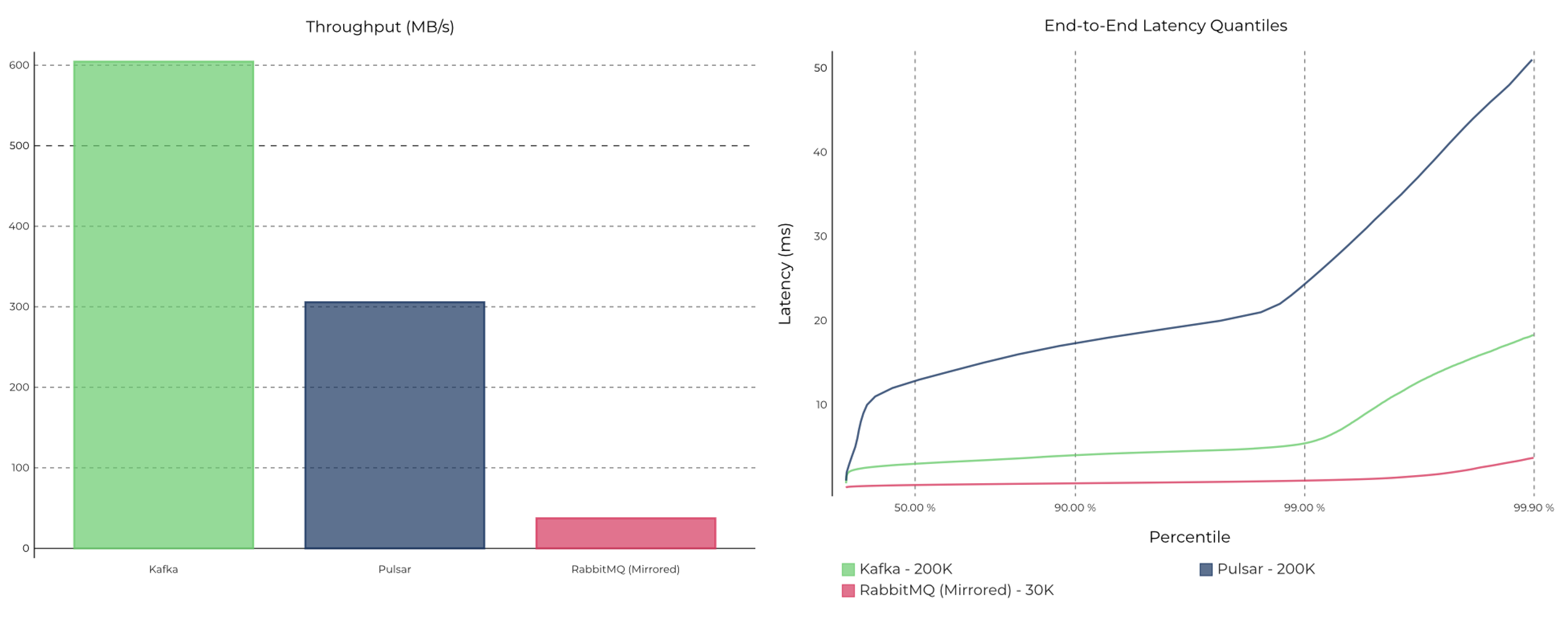 |
(이미지 출처: Benchmarking Kafka vs. Pulsar vs. RabbitMQ: Which is Fastest? (confluent.io))
Kafka, Pulsar, RabbitMQ를 비교를 볼 수 있다. 처리량이 가장 높은 것은 Kafka이고 응답 속도가 가장 빠른것이 RabbitMQ이다. 처리량과 응답속도를 같이 비교했을 때는 카프카가 단연 독보적이다.
높은 확장성
카프카는 손쉬운 확장이 가능하도록 설계된 애플리케이션이다.
만일 기업의 비지니스가 급속도로 성장하는 도중에 중앙 데이터 파이프라인을 담당하는 시스템의 성능 한계로 확장할 수 없다면 비지니스 성공을 가로막는 걸림돌이 될 것이다. 또한 미래 상황을 정확하게 예측을 하기가 어렵다. 카프카는 이러한 요구사항에서 손쉽게 확장 가능하도록 설계되어 있다.
고가용성
카프카 초기에는 메시지를 빠르게 처리하는 것이 목표였지만 점점 고가용성 측면도 중요하게 여기게 되었다. 2013년에 카프카는 클러스터 내 리플리케이션(Replication) 기능을 추가했고 이를 통해 카프카 클러스터의 고가용성이 확보되었다.
내구성
프로듀서는 카프카로 메시지를 전송할 때 프로듀서의 acks라는 옵션을 조정하여 메시지의 내구성을 강화할 수 있다. 프로듀서에 의해 카프카로 전송되는 모든 메시지는 안전한 저장소인 카프카 로컬 디스크에 저장된다. 다른 메시징 시스템의 경우 컨슈머가 메시지를 소비함과 동시에 저장소에서 삭제가 되지만 카프카는 메시지가 삭제되지 않고 일정 시간 또는 크기 만큼 로컬 디스크에 보관된다. 버그나 장애가 발생하더라도 과거의 메시지를 불러와 재처리할 수 있다. 메시지는 브로커 한대에만 저장되는 게 아니라 브로커 중 한대가 종료되더라도 다른 브로커의 로컬 디스크에서 저장된 내용을 바탕으로 복구할 수 있다.
개발 편의성
메시지 전송을 하는 프로듀서(Producer)와 메시지를 가져와 소비하는 컨슈머(Consumer)가 완벽하게 분리되어 동작해 서로 영향을 주지도 받지도 않고있다. 이러한 구성에 따라 개발자는 원하는 부분만 개발할 수 있다.
또한 개발 편의성을 제공하기 위해 카프카는 카프카 커넥트(Kafka Connect)와 스키마 레지스트리(Schema Registry)를 제공한다.
스키마 레지스트리는 카프카 데이터 활용보다 파싱하는데 많은 시간을 소모하는 매우 비효율적인 현실을 보완하고자 스키마를 정의해서 사용할 수 있도록 개발된 애플리케이션이다.
카프카 커넥트는 엘라스틱서치(Elasticsearch), HDFS등 다양한 소스와 싱크를 제공하므로 개발 편의성을 높일 수 있다. 카프카처럼 클러스터를 구성해 고가용성을 확보하는 방식으로 카프카를 운영한다면 효율적인 장애 대응과 품질 개선이 가능해질 것이다.
운영 및 관리 편의성
카프카는 중앙 메인데이터 파이프라인 역할을 하게 되는데 운영이나 관리의 편의성이 떨어진다면 그러한 주요 역할을 맡기기에 부담스러울 수 있다. 한 시스템에서 중요한 역할을 맡고있다면 성능 확장을 위한 증설 작업이 쉬워야하고 간단해야하고 최신 버전이 릴리스되는 경우 무중단으로 버전 업그레이드도 가능해야 한다.
출처
| [실전 카프카 개발부터 운영까지 | 고승범 | 책만 - 교보문고 (kyobobook.co.kr)](http://www.kyobobook.co.kr/product/detailViewKor.laf?mallGb=KOR&ejkGb=KOR&barcode=9791189909345) |