리눅스 컨테이너
리눅스 커널을 공유하면서 프로세스를 격리된 환경에서 실행하는 기술이다. 하드웨어 가상화를 하는 VM(Virtual Machine)과 달리 커널을 공유하는 방식이기 때문에 실행 속도가 빠르다. 프로세스는 커널을 공유하지만 리눅스 네임스페이스, 컨트롤 그룹, 루트 디렉터리 격리 등의 커널 기능을 활용해 격리되어 실행된다. 이러한 격리기술 덕분에 호스트는 프로세스로 인식하지만 컨테이너 관점에서는 독립적인 환경을 가진 가상 환경으로 보인다.
사용해야 하는 이유
컨테이너는 애플리케이션을 환경에 구애 받지 않고 실행하는 기술이다. 가령 서버에 깃랩을 설치해야 하는데 우분투 환경의 경우는 깃랩 설치는 다음과 같은 방식으로 설치해야한다고 가이드 되어있다.
# ubuntu
sudo apt-get update
sudo apg-get install -y curl openssh-server ca-sertificates
sudo apt-get install -y postfix
curl https://packages.gitlab.com/install/repositories/gitlab/gitblab-ee/script.deb.sh | sudo bash
sudo EXTERNAL_URL="http://gitlab.exmple.com" apt-get install gitlab-ee
하지만 만약 다른 서버에도 깃랩을 설치해야하는데 centOs라면 어떨까?
# centOS
sudo yum install -y curl policycoreutils-python openssh-server
sudo systemctl enable sshd
sudo systemctl start sshd
sudo firewall-cmd --permanent --add-service=http
sudo systemctl reload firewalld
sudo yum install postfix
sudo systemctl enable postfix
sudo systemctl start postfix
curl https://packages.gitlab.com/install/repositories/gitlab/gitlab-ee/script.rpm.sh | sudo bash
sudo EXTERNAL_URL="http://gitlab.example.com" yum install -y gitlab-ee
만일 또다른 환경에서 깃랩을 설치하려고 하면 그에 맞는 명령어를 실행하고 실행환경을 갖춰야할 것이다. 그러나 컨테이너를 사용하게 된다면 어떤 환경이든 상관없이 깃랩을 실행할 수 있다. 깃랩이 이미 설치된 이미지를 만들어서 컨테이너로 만들면 되는 것이다. 이미지라는 것은 뒤에서 설명하겠다.
그럼에도 사용해야 하는 이유가 잘 와닿지 않음
애플리케이션 실행을 위해서 실행환경을 맞추어주어야 하는데 A서버는 1년전에 구성했고, B서버는 오늘 구성했다고 가정해본다. 운영체제 버전부터 컴파일러, 설치된 패키지 등이 완벽하게 일치하기란 쉽지 않을 것이다. 이러한 차이점으로 장애가 일어났을때 A서버는 왜 되는거고 B서버는 왜 안되는건가?와 같은 일들이 벌어질 수 있는 것이다. 이렇게 서로 모양이 다른 서버들이 존재하는 상황을 눈송이 서버(Snowflakes Server)라고 한다.
때문에 B서버는 멀쩡하고 A서버가 문제가 생겼을 때 A서버를 잘 아는 사람사람이 필요하다. 또는 운영기록을 서버별로 기록을 해서 해결을 해야할 것이다. 서버가 더 많아지면 더 큰문제가 될 것이다.
아파치 보안 권장 업데이트 사항이있어서 서버별로 아파치를 새로 설치하고 설정파일도 복사하여 옮긴다음에 서버 하나하나 정상으로 띄워졌는지 확인을 해야했다. 만일 기존에 설치됐던 아파치 서버의 버전이 다르다던지 설정파일의 설정이 서버별로 조금씩 다르다면 문제가 생길수도 있다. 또 훗날 서버가 추가되었을 때의 운영체제의 기준이 기존에 사용하던 아파치와는 다를수도 있다.
이러한 애플리케이션의 의존성 문제들과 서로간의 버전차이 환경차이 때문에 컨테이너 기술을 사용하는 것이 전략적으로 더 유리할 수 밖에 없는것이다.
주요 특징
- 운영체제 수준의 가상화: 운영체제 수준에서 가상화를 한다. 무슨 말이냐 하면 별도의 하드웨어 에뮬레이션 없이 리눅스 커널을 공유한 컨테이너를 실행하기 때문이다.
- 빠른 속도와 효율성: 하드웨어 에뮬레이션이 없기 때문에 컨테이너는 아주 빠르게 실행된다. 프로세스 격리를 위해 아주 약간의 오버헤드가 있지만 일반적인 프로세스를 실행하는 것과 거의 차이가 없다. 또한 하나의 머신에서 프로세스만큼 많이 실행하는 것이 가능하다.
- 높은 이식성(portability): 모든 컨테이너는 호스트 환경이 아닌 독자적인 실행 환경을 가지고 있다. 이 환경은 파일들로 구성되어 있으며 이미지 형식으로 공유될 수 있다. 리눅스 커널을 사용하고 같은 컨테이너 런타임을 사용할 경우 컨테이너의 실행 환경을 공유하고 손쉽게 재현할 수 있다.
- 상태를 가지지 않음(stateless): 컨테이너가 실행되는 환경은 독립적이어서 다른 컨테이너에게 영향을 주지 않는다. 도커와 같은 이미지 기반으로 컨테이너를 실행하는 경우 특정 실행 환경을 재사용할 수 있다.
컨테이너는 어떻게 독립된 환경을 갖는가?

호스트 OS는 기본적으로 root (/) 폴더를 갖는다. 리눅스는 chroot를 사용해서 커스텀한 root 디렉토리를 만들 수 있는데 위 그림과 같이 chroot라는 폴더를 root로 만들어서 프로세스의 루트 디렉토리를 변경할 수가 있다. chroot jail로 분리된 프로세스는 chroot 바깥의 디렉토리에는 접근을 할 수 없다. 대신 호스트는 해당 chroot 내부로 접근할 수 있다. chroot에 어플리케이션을 실행할 수 있는 binaries와 libraries를 만들고 해당 실행환경에서 애플리케이션을 실행하게 된다.
리눅스 네임스페이스(Linux Namespace)
VM에서는 각 게스트 머신별로 독립적인 공간을 제공하고 서로가 충돌하지 않도록 하는 기능을 갖고있다. 리눅스에서는 이와 동일한 역할을 하는 namespaces 기능을 커널에 내장하고 있다.
리눅스 네임스페이스는 프로세스를 실행할 때 시스템의 리소스를 분리해서 실행할 수 있도록 도와주는 기능이다. 한 시스템의 프로세스들은 시스템의 리소스들을 공유해서 실행된다. 이를 단일 네임스페이스로 볼 수 있다. 실제로는 1번 프로세스(init)에 할당되어 있는 네임스페이스들을 자식 프로세스들이 모두 공유해서 사용하는 구조로 이루어져있다.
init 프로세스: 리눅스 커널 부팅완료 뒤 처음으로 실행되는 프로세스다. init는 커널이 직접 실행하는 유일한 프로세스다. init을 제외한 나머지 모든 프로세스의 조상이된다. init는 프로세스와 시스템의 초기화 관리를 수행한다.
리눅스에서는 프로세스를 실행할 때 각 네임스페이스 별로 분리해서 실행하는 것이 가능하다. 기본적으로 1번 프로세스의 네임스페이스를 공유해서 실행된다.
PID(프로세스)
프로세스의 ID를 격리할 수 있는 네임스페이스다. 리눅스에서 PID는 init가 1 나머지는 1보다 큰 PID를 부여받는다. PID 네임스페이스를 분리하면 다시 1부터 시작한다. 다만 이 프로세스는 디폴트 네임스페이스와 PID 네임스페이스에 둘 다 속하게 되고, 분리된 새로운 네임스페이스에는 PID가 1부터 시작하지만 디폴트 네임스페이스에서는 1보다 큰 PID를 가지게 된다.
NET(네트워크)
프로세스의 네트워크 환경을 분리할 수 있는 네임스페이스이다. 네트워크 환경을 분리하면 네임스페이스에 새로운 IP를 부여하거나 네트워크 인터페이스를 추가하는 것이 가능하다.
UTS(hostname)
UTS 네임스페이스는 호스트 네임과 NIS 도메인 이름을 격리하는 네임스페이스다. 네트워크 네임스페이스와 함께 네트워크를 격리하는 용도로 사용된다.
MNT(파일시스템 마운트)
호스트 파일시스템에 구애받지 않고 독립적으로 파일시스템을 마운트하거나 언마운트 가능하다.
IPC(SystemV IPC)
프로세스간의 독립적인 통신통로 할당
namespaces를 지원하는 리눅스 커널을 사용하고 있으면 다음 명령어로 namespace를 만들어 실행할 수 있다.
sudo unshare --fork --pid --mount-proc bash
ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.2 115544 2044 pts/0 S 15:50 0:00 bash
root 12 0.0 0.1 155448 1848 pts/0 R+ 15:50 0:00 ps aux
PID namespace에 실행한 bash가 PID 1로 할당되어 있다(일반적으로는 init가 1이다)
PID namespace 안에서 실행한 프로세스를 밖에서도 보자
top
ps aux | grep top
root 9710 0.0 0.0 34716 2988 pts/0 S+ 16:29 0:00 top
가둬서 실행했던 PID namespace 밖의 공간에서도 프로세스를 확인할 수 있다는 것을 알았다. 즉 namespaces 기능은 같은 공간을 공유하되 조금 더 제한된 공간을 할당해주는 것이라 볼 수 있다.
namespace를 통해 독립적인 공간을 할당한 후에는 nsenter명령어를 통해 이미 돌아가고 있는 namespace 공간에 접근할 수 있다. docker에서는 docker exec와 유사하지만 nsenter의 경우는 cgroups에 들어가지 않기 때문에 리소스 제한의 영향을 받지 않는다.
CGROUPs(Control Groups)
cgroups는 자원에 대한 제어를 가능하게 해주는 리눅스 커널의 기능이다. cgroups는 다음 리소스를 제어할 수 있다.
- 메모리
- CPU
- I/O
- 네트워크
- device 노드(/dev/)
리눅스에서는 다음과 같은 명령어를 사용해 메모리를 제어할 그룹을 생성할 수 있다.
sudo cgcreate -a ssut -g memory:testgrp
위 명령어는 ssut 유저가 소유하고 메모리를 제어할 testgrp를 생성하는 것이다. 이러면 /sys/fs/cgroup/*/groupname 경로내에 있는 파일을 통해 그룹의 여러 옵션들을 변경할 수 있다.
echo 2000000 > /sys/fs/cgroup/memory/testgrp/memory.kmem.limit_in_bytes
위와 같이 파일을 수정했을 때는 메모리 최대 사용량을 2MB로 제한할 수 있다.
sudo cgexec -g memory:testgrp bash
top
top: error while loading shared libraries: libgpg-error.so.0: failed to map segment from shared object
위와 같이 명령어를 입력하면 생성한 testgrp 에서 bash셸을 실행시켜 메모리 제한이 잘 먹히고 있는지 확인해 볼 수 있다.
도커(Docker)

컨테이너 기반의 오픈소스 가상화 플랫폼이다. 컨테이너를 표준화된 방법으로 생성하고 관리할 수 있는 플랫폼이라고 보면 된다.
LXC, LibContainer, runC 등은 위에서 설명한 cgroups, namespaces를 표준으로 정의해둔 OCI(Open Container Initative) 스펙을 구현한 컨테이너 기술의 구현체다. LXC는 Canonical이 지원하고 있는 리눅스 컨테이너 프로젝트로 Docker 1.68 이전버전까지 LXC를 이용해 구현해서 사용했다. 이후에 Docker는 libcontainer -> runC (libcontainer의 리팩토링 구현체)로 자체 구현체를 갖게 되었다.
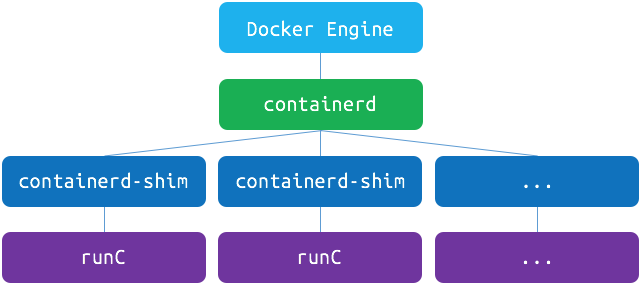
docker는 1.11 버전부터 실제로 위와 같은 구조로 작동하고 있다. containerd는 OCI 구현체를 이용해 container를 관리해주는 daemon이다. docker engine 자체는 이미지, 네트워크, 디스크 등의 관리 역할을 하고 있으며, 여기서 Docker engine과 containered각각이 완전히 분리된 덕분에 Docker engine 버전을 올릴 때 Docker engine을 재시작해도 container 재시작 없이 사용할 수 있게 된다.
이미지란
컨테이너는 독립된 파일시스템을 사용한다. 도커는 이러한 커스텀한 파일시스템은 컨테이너 이미지로 제공한다. 이미지가 컨테이너 파일시스템을 포함하고 있으므로 애플리케이션 구동에 필요한 모든 디펜던시, 설정, 스크립트, 바이너리 등을 가지고 있어야한다. 이러한 이미지는 환경변수나 실행하기 위한 디폴트 명령어나 다른 메타 데이터등의 설정 정보 또한 포함한다.
이미지는 컨테이너 실행에 필요한 파일과 설정값등을 포함하는 것으로 상태값을 가지지 않고 변하지 않는다(Immutable). 컨테이너는 이미지를 실행한 상태라고 볼 수 있다. 추가되거나 변하는 값은 컨테이너에 저장되고 이를 이미지로 다시 만들 수도 있다. 같은 이미지에서 여러개의 컨테이너를 생성할 수 있고 상태가 바뀌거나 삭제되더라도 이미지는 변하지 않고 그대로 남는다.
ubuntu 이미지는 ubuntu를 실행하기 위한 모든 파일을 가지고 있고 MySQL은 debian 기반 MySQL을 실행하는데 필요한 파일과 명령어, 포트 정보등을 가지고 있다.
말그대로 이미지는 컨테이너를 실행하기 위한 모든 정보를 가지고 있기 때문에 의존성 파일을 컴파일하고 이것저것 설치할 필요가 없다.
그래서 도커가 핫한 이유?
컨테이너는 리눅스에서 존재했던 기술이지만, 그러나 컨테이너를 만들때 사용하는 isolate기술들을 잘 조합해서 사용자가 사용하기 쉽게 만드는 것은 없었고, 사용자들이 원하는 기능을 간단하지만 획기적인 아이디어로 구현했다.
레이어 저장방식
도커 이미지는 컨테이너를 실행하기 위한 모든 정보를 가지고 있기 때문에 보통 용량이 수백 메가 바이트에 이른다. 처음 이미지를 받을 땐 부담이 안되지만 기존 이미지에 파일 하나를 추가했다고 수백메가를 다시 다운받으면 비효율 적일것이다.
이런 문제를 해결하고자 도커는 레이어(layer)라는 개념을 사용하고 있다. 유니온 파일 시스템을 이용하여 여러개의 레이어를 하나의 파일시스템으로 사용할 수 있게 해준다. 이미지는 여러개의 읽기 전용 레이어로 구성되고 파일이 추가되거나 수정되면 새로운 레이어가 생성된다. 만들어진 새로운 이미지를 받는다면 변경된 레이어를 받으면 되는 것이다.
컨테이너를 생성할 때도 레이어 방식을 사용하는데 기존의 이미지 레이어 위에 읽기/쓰기 레이어를 추가한다. 이미지 레이어를 그대로 사용하면 컨테이너가 실행중에 생성하는 파일이나 변경된 내용은 읽기/쓰기 레이어에 저장되므로 여러개의 컨테이너를 생성해도 최소한의 용량만 사용한다.
Dockerfile
도커는 이미지를 만들기 위해 Dockerfile이라는 자체 DSL(Domain-specific language) 언어를 이용하여 이미지 생성 과정을 적는다.
서버에 어떤 프로그램을 설치하는 과정을 Dockerfile에 기록해 관리하면 된다. 이 파일은 소스와 함께 버전관리되고 원한다면 누구나 이미지 생성과정을 보고 수정할 수 있다.
Dockerhub
도커의 이미지는 용량이 큰 경우도 흔하다. 이런 큰용량의 이미지를 서버에 두기는 쉽지 않기 때문에 Docker hub를 통해 공개 이미지를 무료로 관리해준다.
Command와 API
도커 클라이언트의 커맨드 명령어는 직관적이며 컨테이너를 잘 이해하지 못하더라도 편하게 사용할 수가 있다.
참고
| [컨테이너란? 리눅스의 프로세스 격리 기능 | 44BITS](https://www.44bits.io/ko/keyword/linux-container) |
| [왜 굳이 도커(컨테이너)를 써야 하나요? - 컨테이너를 사용해야 하는 이유 | 44BITS](https://www.44bits.io/ko/post/why-should-i-use-docker-container) |
| [UTS 네임스페이스를 사용한 호스트네임 격리 - 컨테이너 네트워크 기초 1편 | 44BITS](https://www.44bits.io/ko/post/container-network-1-uts-namespace) |
I’m in Chroot Jail, Get Me Out of Here! – Security Queens