oracle rac(Real Application Cluster)란
Oracle RAC는 여러개의 오라클 Instance가 하나의 Database에 접근할 수 있다. 이는 application에서 접속할 수 있는 통로는 여러 개이며 database는 하나인 형태이다.
RAC로 연결된 N개의 Instance에서 동일한 Datafile을 공유하여 엑세스한다. 그러나 Database 작업에 사용할 수 있는 cpu나 메모리 등의 resource는 서로 공유하지 않으며 해당 Node의 Resource만 사용한다.
왜 사용하는가
-
single server
오라클 Instance에 장애가 발생했을 때 Storage에 접근할 수 없게되는 문제가 생긴다 -
HA(High Availability)
똑같은 장비 두개를 구축해서 하나는 실제 서비스(active), 하나는 대기 상태(standby)로 두는 방식으로 구성, 그래서 active 상태였던 서버가 고장나면 standby 상태의 서버가 즉시 active 상태로 바뀌어 투입되어 서비스 중단이 되지 않도록 조치하는 구성, 문제는 비용이 많이 들고 동기화 문제가 생긴다.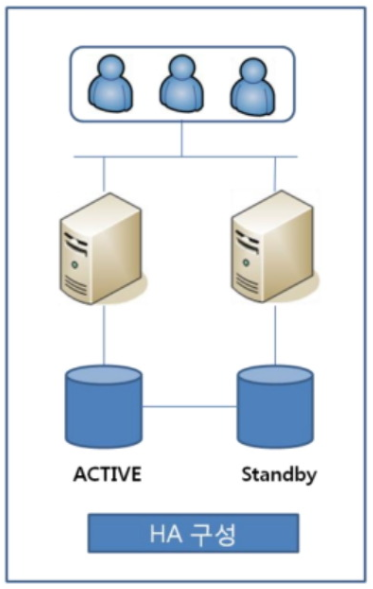
-
OPS(Oracle Parallel Server)
하나의 storage에 두 개의 instance가 연결되어 있는 구성으로, 사용자가 각각 다른 Instance에 접속을 해도 storage가 하나이므로, 같은 데이터를 조회 변경할 수 있다.
storage에 저장된 데이터를 a사용자가 instance1로 데이터 변경 후 commit하고 b사용자가 instance2에서 조회를 하려면 우선 storage에 저장되는 것을 기다린 후 instance2로 가져와야 한다. 디스크를 사용해서 시간이 오래걸리는 작업이다. 이를 RAC ping 문제라고 한다.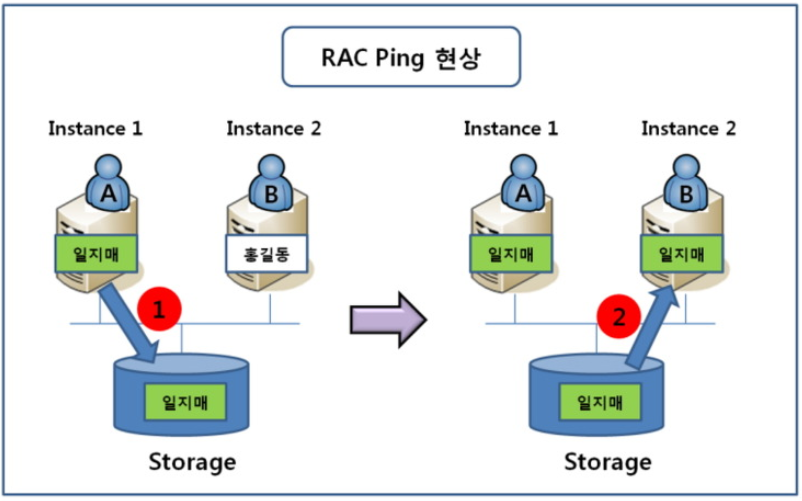
-
RAC(Real Application Cluster) OPS의 RAC ping 문제가 개선되어 크게 향상되어, oracle 9i 버전부터 서로 다른 instance 에서 변경된 데이터를 디스크를 거치지 않고 바로 instance로 가져올 수 있는 기능, cache fusion이라는 기능이 사용된다.
cluster
두 개 이상의 독립된 서버들과 Disk를 하나로 연결하는 기법이다. 사용자가 Cluster로 구성된 서버들 중 어느 서버로 접속해도 동일한 Disk를 액세스를 하게 되는 것이다.
오라클 RAC는 Oracle Clusterware를 사용하여 어느 Instance에 접속하여도 사용자에게 동일한 data를 실시간으로 조회, 변경할 수 있는 기능을 제공한다.
단일 Instance vs Oracle RAC
단일 Instance 환경에서와 마찬가지로 오라클 RAC 환경의 각 Instance에는 각자의 SGA와 백그라운드 프로세스가 존재한다. 그러나 모든 Datafile과 Control File은 모든 인스턴스에서 동일하게 액세스 할 수 있어야 하므로 공유 Storage에 위치한다.
각 Instance에는 고유한 Online Redo Log File이 존재한다. Online Redo Log File은 자신이 속한 Instance에 의해서만 기록될 수 있다. 그러나 Online Redo Log File도 인스턴스 복구 시에는 다른 인스턴스에서 액세스 할 수 있어야 한다. 따라서 Online Redo Log File도 공유 Storage에 저장되어야 한다.
Oracle RAC 구성요소

Grid Infrastructure에서 제공하는 oracle clusterware의 기반하에 여러 database 서버를 묶어서 하나의 시스템 처럼 동작하도록 지원한다.
공유 storage
각 instance는 공유 storage를 통해 물리적인 data를 공유하며 database에서 사용하는 ASM 및 CFS(Cluster File System)를 구성한다. 공유 Storage에서 Database File은 모든 Node에 동등하게 동시에 액세스 할 수 있어야 한다. 물론 Storage에서 생성된 Disk는 공유 모드가 활성화 되어야 한다.
network
- public ip : 각 node에 대한 ip로 서버 주소와 동일하다
- service ip : 클라이언트에서 database 서버의 public ip를 사용하여 접속할 경우 장애가 발생한 node에서 세션을 다른 node로 옮기는데 시간이 많이 걸릴 수 있다. 이때 vip를 사용하여 클라이언트가 node에 장애가 발생했다는 것을 신속하게 인식할 수 있도록 하여 다른 node 재연결 시간을 향상 시킬 수 있다.
- scan(single client access name) : gns 및 dns를 사용하여 정의할 수 있다. scan을 이용할 경우 cluster 내 서버 수에 관계없이 load balancing 및 고가용성을 고려하여 3개의 ip 주소를 권장한다.
- private ip : cluster node 별 통신을 위한 ip로 다음과 같은 목적으로 사용한다
- resource 동기화를 위해 cluster에서 heartbeat 프로세스를 위해사 사용하는 통신경로
- instance에서 다른 instance로 data를 전송하는 용도로 사용