조인은 테이블 또는 view와 같은 두 개의 row들을 결합하여 하나의 row를 반환한다. 조인은 SQL문의 WHERE FROM 혹은 JOIN 으로 결정된다
트리 조인
일반적으로 join tree는 거꾸로 된 트리 구조로 표시된다.
아래 그림과 같이 테이블이 있을 때 옵티마이저는 왼쪽에서 오른쪽으로 조인을 진행한다.

입력이 이전 조인으로부터의 결과의 조인이라면, 조인 트리의 모든 내부 노드의 오른쪽 child가 테이블인 경우 트리는 left deep join tree 가 된다.

join tree의 모든 내부 노드의 왼쪽 child가 테이블인 경우 right deep join tree 라고 한다.

join tree의 내부 노드의 왼쪽 또는 오른쪽 child가 join 노드가 될수 있는 경우 bushy join tree라고 한다.

옵티마이저가 Join 구문을 실행하는 방법
-
Access paths
옵티마이저는 무조건 조인 구문에 있는 각 테이블의 데이터를 서칭을 위해 access path를 선택해야한다.
-
Join Methods
각 row sources 쌍을 조인하기 위해 오라클 데이터베이스는 join을 어떻게 할 것인지에 대한 방법을 정해야한다. 조인이 가능한 메서드로는 nested loop, sort merge, hash join이 있다. Cartesian join은 앞의 조인 메서드중 하나가 필요하다. 각 조인 방법에는 다른 방법보다 더 적합한 특정 상황에서 쓰인다.
-
Join Types
조인 조건은 조인 타입을 결정한다. 예를 들어 inner join은 오로지 조인 조건과 매칭되는 row를 찾는다. outer join은 매치되지 않는 것도 찾는다
-
Join Order
세 개 이상의 테이블 조인 구문을 수행하기 위해 오라클 데이터베이스는 테이블을 조인하고 조인 결과를 다음 테이블에 조인한다. 이 프로세스는 모든 테이블이 조인되어 결과가 나올 때까지 지속된다.
옵티마이저가 join 계획을 선택하는 방법
조인 순서 및 메소드를 결정할 때 옵티마이저의 목표는 SQL문 실행 전체에서 수행되는 작업을 줄이기 위해 행 수를 조기에 줄이는 것이다.
- 최적화 프로그램은 둘 이상의 테이블을 조인하면 row sources에 최대 하나의 row가 포함되는지 여부를 결정한다.
- outer join 조건이 있는 조인문의 경우 outter join 연산자가 있는 테이블은 일반적으로 조인 순서에서 조건의 다른 테이블 뒤에 온다
옵티마이저는 다음과 같은 방법으로 비용을 예측한다
- nested loop join의 비용은 외부 테이블의 선택된 각 row와 내부 테이블의 일치하는 각 행을 메모리로 읽는 비용에 따라 달라진다. 최적화 프로그램은 데이터 사전의 통계를 사용하여 이러한 비용을 추정한다
- sort merge join의 비용은 모든 원본 메모리로 읽고 정렬하는 비용에 따라 크게 달라진다
- hash join 비용은 조인의 입력 측 중 하나에 hash table을 작성하고 조인의 다른 쪽에 있는 row를 사용하여 이를 조사하는 비용에 따라 크게 달라진다.
Nested Loops Joins
조인으로 묶이는 한 쪽 테이블을 외부 테이블로 설정하고 다른 한 쪽을 내부 테이블로 설정해서 외부에서 반복하며 외부 테이블을 한 행씩 돌아서 내부 테이블과 매칭시키는 방식으로 이루어진다.
Hash Joins
- join 컬럼에 적당한 인덱스가 없어 NL join이 비효율적일때
- join access량이 많아 random access 부하가 심하여 nested join이 비효율적일 때
- sort merge join을 하기에는 두 테이블이 너무 커 sort 부하가 심할 때
- 수행빈도가 낮고 쿼리 수행시간이 오래 걸리는 대용량 테이블을 join할 때
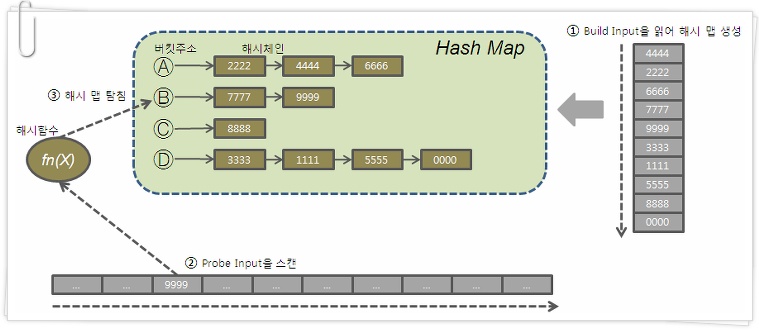
- 둘 중 작은 집합을 읽어 Hash Area에 해시 테이블을 생성한다.
- 반대쪽 큰 집합을 읽어 해시 테이블을 탐색하면서 join 한다.
- 해시 함수에서 리턴 받은 버킷 주소로 찾아가 해시 체인을 스캔하면서 데이터를 찾는다.
Sort Merge Joins
- 연결 고리에 인덱스가 전혀 없는 경우
- 대용량 자료를 조인할때 유리한 경우
- 조인 조건으로 범위 비교 연산자가 사용된 경우
- 인덱스 사용에 따른 랜덤 액세스의 오버헤드가 많은 경우
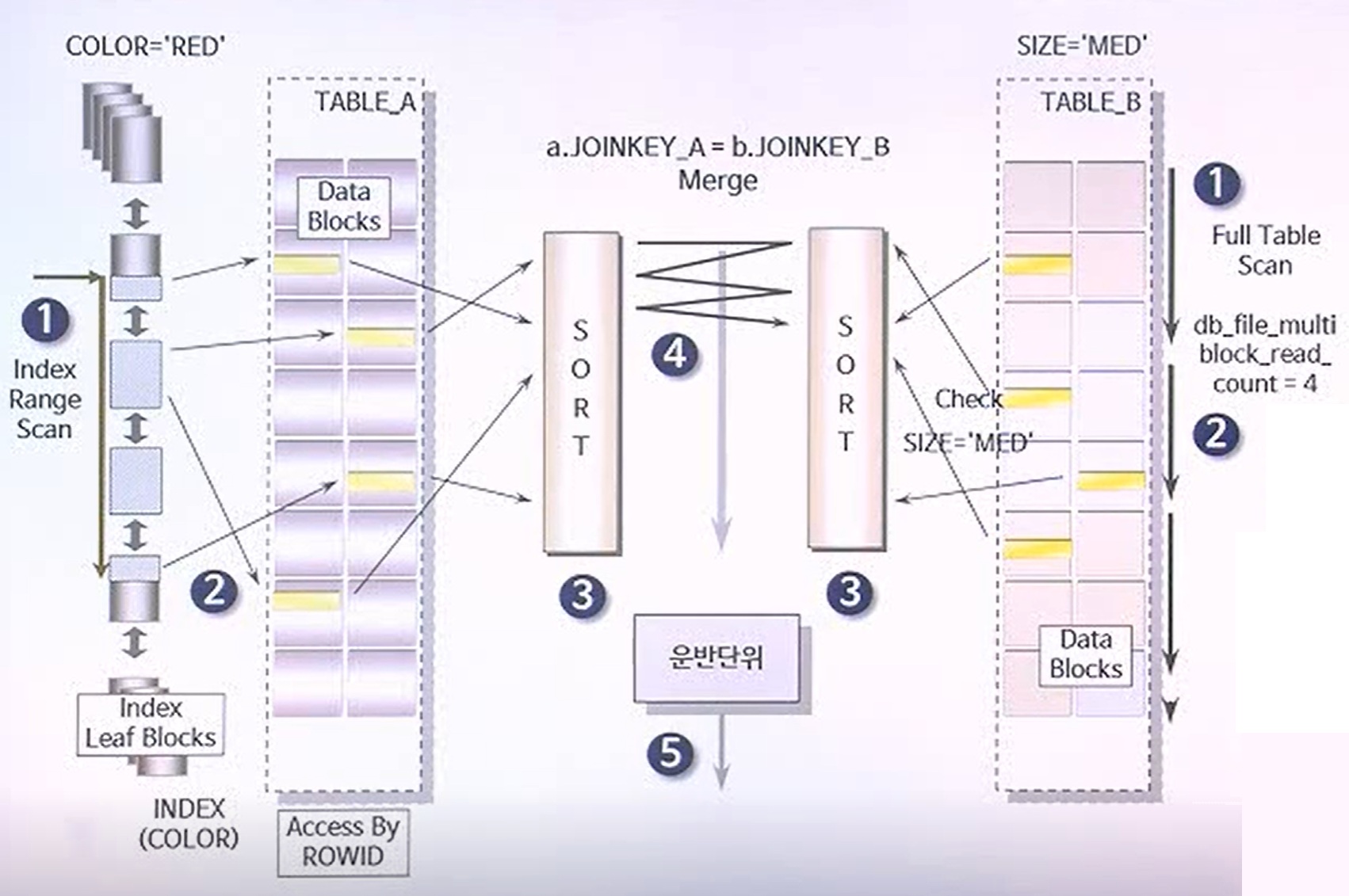
- 각 테이블에 대해 동시에 독립적으로 데이터를 먼저 읽어 들인다
- 읽혀진 각 테이블의 데이터를 조인을 위한 연결고리에 대하여 정렬을 수행한다
- 정렬이 모두 끝난 후에 조인 작업이 수행한다.