파드 컨테이너 자동 복구 방법
셀프 힐링(Self-Healing)
파드를 자동으로 복구하는 기술이다. 제대로 작동하지 않는 컨테이너를 다시 시작하거나 교체해 파드가 정상적으로 작동하게 한다.
테스트
$ kubectl exec -it nginx-pod -- /bin/bash
파드에 접속한다.
$ cat /run/nginx.pid
nginx의 PID를 확인한다.
$ ls -l /run/nginx.pid
프로세스가 생성된 시간을 확인한다.
새로운 터미널을 켠다
$ i=1; while true; do sleep 1; echo $((i++)) `curl --silent 172.16.103.132 | grep title` ; done
지속적으로 nginx 웹으로 요청을 보내는 스크립트를 실행한다.
컨테이너로 돌아와 pid를 죽인다
$ kill 1
nginx 웹 페이지를 받아오는 스크립트가 잘 작동하는지 확인하고 자동으로 다시 복구되는지도 함께 확인한다.
복구 이후에 다시 nginx-pod로 접속한다. ls -l을 실행한다.
$ kubectl exec -it nginx-pod -- /bin/bash
$ ls -l /run/nginx.pid
날짜가 변경되어있는지 확인한다.
POD 동작 보증 기능
쿠버네티스는 파드 자체에 문제가 생기면 파드를 자동 복구해서 파드가 항상 동작하도록 보장하는 기능이 있다.
deployment의 replication pod중 하나를 삭제해보자
먼저 pod가 몇개 있는지를 먼저 확인한다
$ kubectl get pods
그 이후에 pod 하나를 삭제한다.
$ kubectl delete pods echo-hname-test
잘 삭제되어 있는지 목록을 확인하면 개수의 변화 없는 것을 확인할 수 있다.
이 이유는 deployment를 생성할 때 replicas 수를 정해놨기 때문이다. replicas 파드 수를 항상 확인하고 부족하면 새 파드를 만들어낸다. 파드가 삭제되고 다시 생성되는 방법은 다음과 같다.
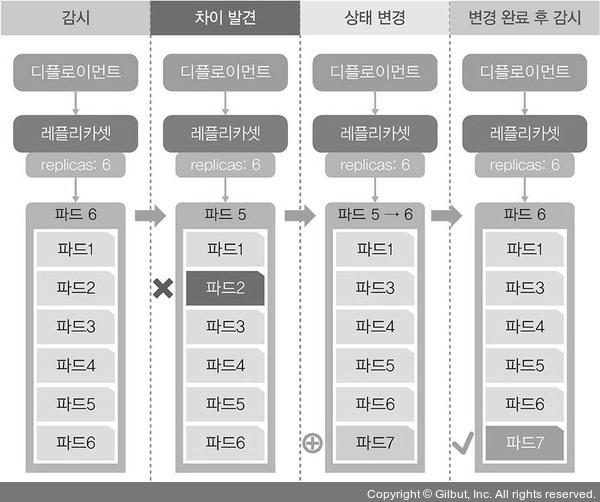
deployment의 pod를 삭제하기 위해서는 deployment를 삭제해야한다.
$ kubectl delete deployment echo-hname
노드 자원 보호하기
노드는 어떻게 관리할까? 노드는 쿠버네티스 스케줄러에서 파드를 할당받고 처리하는 역할을 한다. 자주 문제가 발생하는 노드에 파드를 할당해야하는 경우도 있다. 이런 경우 노드에 문제가 생기더라도 파드의 문제를 최소화한다. 하지만 쿠버네티스는 모든 노드에 균등하게 파드를 할당하려고한다. 그렇다면 어떻게 문제가 생길 가능성이 있는 노드라는 것을 쿠버네티스에 알려줄까?
쿠버네티스에서는 이러한경우 cordon 기능을 사용한다.
kubectl cordon은 지정된 노드에 더이상 pod가 스케쥴링 되서 실행되지 않도록 한다.
$ kubectl cordon dev-umon-kube-test002-ncl

이 상태에서는 dev-umon-kube-test002-ncl에 이미 할당되어 있는 pod들 외에는 더이상 pod가 할당되지 않는다.
이 상태를 해결하고싶으면 uncordon 명령어를 사용한다.
$ kubectl uncordon dev-umon-kube-test002-ncl
노드 유지보수하기
쿠버네티스를 사용하다보면 노드의 커널을 업데이트하거나 노드의 메모리를 증설하는 작업이 필요해 노드를 꺼야하는 경우도 있다. 이런 경우를 대비해 쿠버네티스는 drain 기능을 제공한다. drain은 지정된 노드의 pod를 다른 곳으로 이동시켜 해당 노드를 유지보수할 수 있게 한다.
-
kubectl drain 명령을 실행해 유지보수할 노드를 pod가 없는 상태로 만든다. 그런데 이 명령을 실행하면 해당 노드에 데몬셋을 지울 수 없어서 명령을 수행할 수 없다고 나온다.
$ kubectl drain dev-umon-kube-test003-ncldrain은 실제 pod를 옮기는 것이 아니라 pod를 삭제하고 다른 곳에 다시 생성한다. DaemonSet은 각 노드에 1개만 존재하는 pod라서 drain으로는 삭제 할 수 없다
-
이번에는 drain과 ignore-daemonsets 옵션을 함께 사용한다. 이 옵션은 DaemonSet을 무시하고 진행한다.
$ kubectl drain dev-umon-kube-test003-ncl --ignore-daemonsets -
노드에 pod가 없는지 확인하면 된다.
-
drain된 노드는 cordon 했을 때처럼 SchedulingDisabled가 된다.
-
유지보수가 끝나면
uncordon명령어로 실행해준다.
pod 업데이트하고 복구하기
pod를 운영하다보면 컨테이너에 새로운 기능을 추가하거나 치명적인 버그가 발생해 버전을 업데이트해야 하는 경우가 있다. 또는 업데이트 도중 문제가 발생해 다시 기존 버전으로 복구해야하는 일이 발생할 수 있다.
pod 업데이트하기
테스트를 위한 pod를 배포해보자
$ kubectl apply -f rollout-nginx.yaml --record
# rollout-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: rollout-nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
conainters:
- name: nginx
image: nginx:1.15.12
여기서 중요한건 버전을 정하는 image: nginx: 1.15.12이다. 여기에 설치할 컨테이너 버전을 지정하고, 설치한 후에 단계별로 버전을 업데이트한다.
record 옵션으로 기록된 히스토리는 rollout history 명령을 실행해 확인할 수 있다.
$ kubectl rollout history deployment rollout-nginx
배포한 pod의 정보를 확인한다.
$ kubectl get pods -o wide
배포한 파드에 속해 있는 nginx 컨테이너 버전을 curl -I 명령으로 확인한다.
$ curl -I --silent 172.16.103.143 | grep Server
set image 명령으로 pod의 nginx 컨테이너 버전을 1.16.0으로 업데이트한다. 이번에도 –record를 명령에 포함해 실행한 명령을 기록한다.
$ kubectl set image deployment rollout-nginx nginx=nginx:1.16.0 --record
업데이트 이후 pod 상태를 확인한다
$ kubectl get pods -o wide
결과를 보면 이름과 IP모두 변경되었다. rollout은 pod를 순차적으로 하나씩 지우고 생성한다. 이 때 pod수가 많으면 하나씩이 아니라 다수의 pod가 업데이트된다. 기본값은 전체의 1/4이고 최소는 1개다
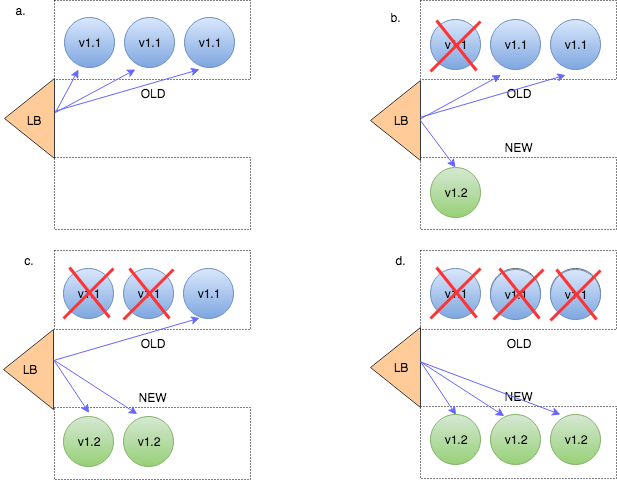
1.16.0으로 모두 업데이트되면 Deployment 상태를 확인한다.
$ kubectl rollout status deployment rollout-nginx
rollout history 명령을 실행해 rollout-nginx에 적용된 명령들을 확인한다.
$ kubectl rollout history deployment rollout-nginx
curl -I 명령으로 업데이트(1.16.0)가 제대로 이루어졌는지도 확인한다.
curl -I --silent 172.16.132.10 | grep Server
업데이트 실패 시 pod 복구하기
업데이트할때 실수로 잘못된 버전을 입력하면 어떻게 되는지 확인해보자
nginx 컨테이너 버전을 1.17.2가 아닌 1.17.23으로 입력해보자
$ kubectl set image deployment rollout-nginx nginx=nginx:1.17.23 --record
pod가 삭제되지 않고 pending 상태에서 넘어가지를 않는다.
$ kubectl get pod -o wide
어떤 문제인지를 확인하기 위해 rollout status를 실행하자. 새로운 replicas는 생성번호나 디플로이먼트를 배포하는 단계에서 대기중으로 더이상 진행되지 않음을 확인할 수 있다.
$ kubectl rollout status deployment rollout-nginx
이럴땐 describe 명령으로 상태를 좀 더 알아보자
$ kubectl describe deployment rollout-nginx
replicas가 새로 생성되는 과정에서 멈춰있다. 그 이유는 1.17.23 버전의 nginx컨테이너가 없기 대문이다. 때문에 replicas가 생성을 시도했으나 이미지가 없어서 deployment가 배포되지 않고 있다. 이를 방지하고자 업데이트할 때 rollout을 사용하고 –record로 기록하는 것이다.
정상적인 상태로 돌아가게 해보자 다음 명령어로 history를 확인하자
$ kubectl rollout history deployment rollout-nginx
rollout undo로 명령 실행을 취소해 마지막 단계에서 전 단계로 되돌린다.
$ kubectl rollout undo deployment rollout-nginx
파드 상태를 다시 확인해보자
$ kubectl get pods
rollout history로 명령을 확인하면 revision 4가 추가되고 revision 2가 삭제 됐다. 현재 상태를 revision 2로 되돌렸기 때문에 revision 2는 삭제되고 가장 최근 상태가 revision 4가 된다.
$ kubectl rollout history deployment rollout-nginx
curl -I로 확인하면 버전이 1.16.0으로 되돌려진 것을 볼 수 있다.
$ curl -I --silent 172.16.132.10 | grep Server
rollout status 명령으로 변경이 정상적으로 적용됐는지 확인할 수 있다.
특정 시점으로 pod 복구하기
특정 시점으로 돌아가기 위해서는 --to-revision 옵션을 사용한다.
$ kubectl rollout undo deployment rollout-nginx --to-revision=1
이후 생성된 pod의 ip를 확인한다. curl 명령어로 확인해보면 1.15.2 버전인 처음으로 돌아가는 것을 확인할 수 있다.